ArborX issueshttps://code.ornl.gov/6da/ArborX/-/issues2020-02-25T17:17:45Zhttps://code.ornl.gov/6da/ArborX/-/issues/231Examine interface and performance implications of having a query index2020-02-25T17:17:45ZArndt, DanielExamine interface and performance implications of having a query index*Created by: aprokop*
Currently, the only way to access the index of a query is to have a user attach it. In many situations, we know the index itself and do not need user info to process it. There are use cases where we need this index...*Created by: aprokop*
Currently, the only way to access the index of a query is to have a user attach it. In many situations, we know the index itself and do not need user info to process it. There are use cases where we need this index. Therefore, we need to see if it makes sense to always have it and treat it ourselves.https://code.ornl.gov/6da/ArborX/-/issues/165Use lower-precision data for bounding volumes2020-03-04T22:07:40ZArndt, DanielUse lower-precision data for bounding volumes*Created by: aprokop*
Some things to consider:
- Does the box size has to be aligned with word size?
- For correctness, the lower-precision AABB bounds must fully enclose the volume of the higher-precision AABB or object
The lower ...*Created by: aprokop*
Some things to consider:
- Does the box size has to be aligned with word size?
- For correctness, the lower-precision AABB bounds must fully enclose the volume of the higher-precision AABB or object
The lower bound of the AABB should be computed by rounding down to the nearest representable single-precision value. The upper bound should computed by rounding up.
There is also an issue that the range of values represented by `float` is smaller than that represented by `double`. Thus, scaling would be required.
- Floats may not be the final answer
For example, [this paper](https://arxiv.org/abs/1901.08088) considers quantized bounds. The scene bounding box is partitioned in $2^10$ bins in each direction, and the bounding boxes are snapped to bin boundaries. This allows to store each bound using only 10 bits, resulting in overall bounding volume of the node taking 64 bit (4 unused), i.e. 8 bytes, compared to 24 required by 4 floats. Together with 2 ints the node size is 16 bytes.https://code.ornl.gov/6da/ArborX/-/issues/145Improve sort2020-04-16T13:34:20ZArndt, DanielImprove sort*Created by: aprokop*
Note that this is different from #60, as that one concerns only scaling.
Here are some results from TIOGA (with CudaUVM). Three variants:
- Upstream master
- Using `unsigned int` for `size_type` template param...*Created by: aprokop*
Note that this is different from #60, as that one concerns only scaling.
Here are some results from TIOGA (with CudaUVM). Three variants:
- Upstream master
- Using `unsigned int` for `size_type` template parameter in Kokkos' BinSort [[here](https://github.com/aprokop/ArborX/blob/dcc40adcc63f6bc253ec31f6050dd969f6e366c2/src/details/ArborX_DetailsSortUtils.hpp#L60)]
- Using Thrust [[here](https://github.com/aprokop/ArborX/blob/78f9a6f7b4d82b892e751a2ed9eefb0a101e3833/src/details/ArborX_DetailsSortUtils.hpp#L55)]

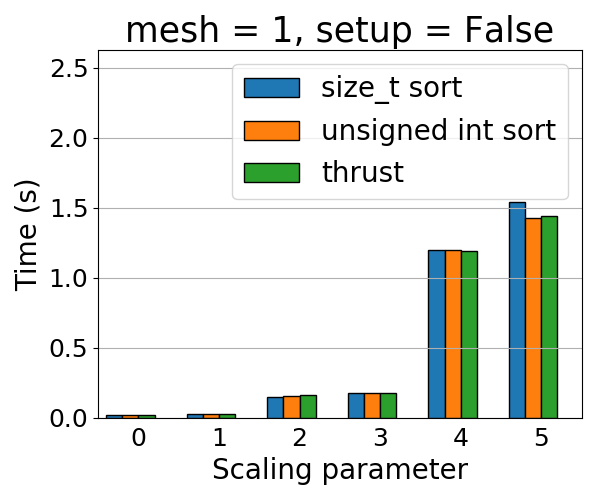
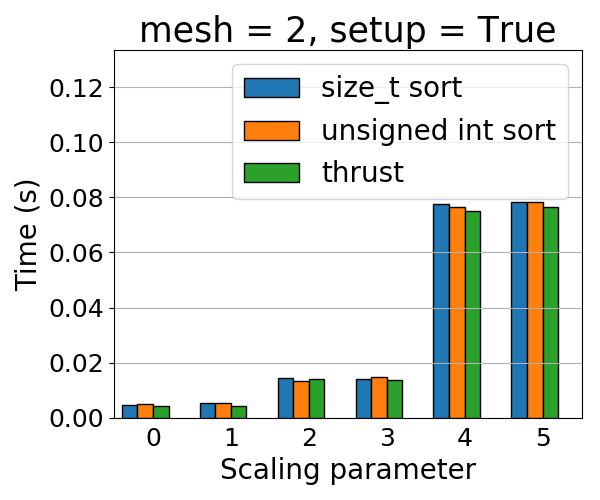
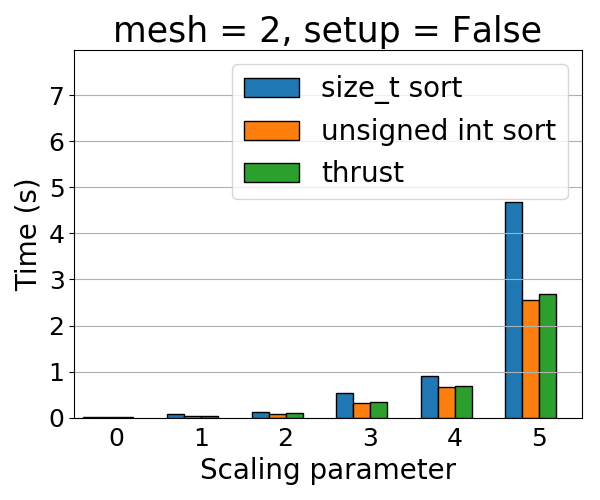
https://code.ornl.gov/6da/ArborX/-/issues/77Check roofline model for ArborX2019-09-15T12:31:10ZArndt, DanielCheck roofline model for ArborX*Created by: aprokop*
Right now, it's unclear where we are at.*Created by: aprokop*
Right now, it's unclear where we are at.https://code.ornl.gov/6da/ArborX/-/issues/60Sorting Morton indices does not scale for small problem sizes2019-05-17T16:35:18ZArndt, DanielSorting Morton indices does not scale for small problem sizes*Created by: aprokop*
The default `bvh_driver` parameters, OpenMP run.
`OMP_NUM_THREADS=1`
...*Created by: aprokop*
The default `bvh_driver` parameters, OpenMP run.
`OMP_NUM_THREADS=1`
```
2.99e-01 sec 10.0% 98.6% 0.0% 96 ArborX:BVH:sort_morton_codes_and_init_leaves [region]
|-> 3.82e-02 sec 1.3% 100.0% 0.0% 96 Kokkos::Sort::BinCount [for]
|-> 1.20e-01 sec 4.0% 100.0% 0.0% 96 Kokkos::Sort::BinBinning [for]
|-> 5.39e-02 sec 1.8% 100.0% 0.0% 96 Kokkos::Sort::BinSort [for]
```
`OMP_NUM_THREADS=2`
```
4.26e-01 sec 14.2% 98.9% 0.0% 93 ArborX:BVH:sort_morton_codes_and_init_leaves [region]
|-> 1.13e-01 sec 3.8% 100.0% 0.0% 93 Kokkos::Sort::BinCount [for]
|-> 2.18e-01 sec 7.3% 100.0% 0.0% 93 Kokkos::Sort::BinBinning [for]
|-> 3.84e-02 sec 1.3% 100.0% 0.0% 93 Kokkos::Sort::BinSort [for]
```
Note: the number of calls slightly different (96 vs 93).
`BinCount` is an order of magnitude slower, `BinBinning` twice as slow.https://code.ornl.gov/6da/ArborX/-/issues/26Decide on the minimum chunk of work for OpenMP2019-05-02T14:13:06ZArndt, DanielDecide on the minimum chunk of work for OpenMP*Created by: aprokop*
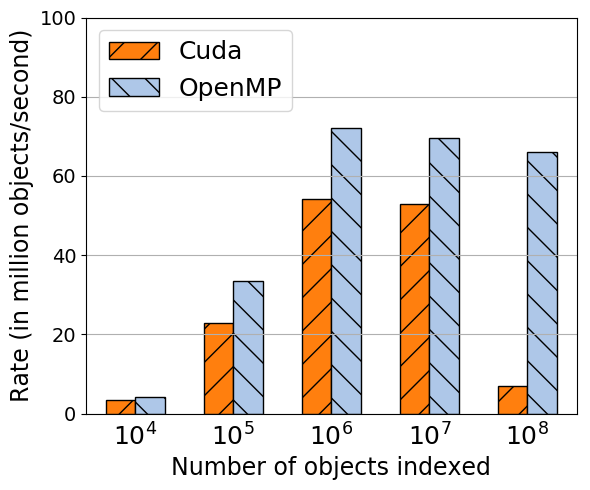
Right now, strong scaling of OpenMP run will start increasing the OpenMP time for smaller problems, once the ratio of objects/thread hits certain threshold. We need to figure out the minimal amount of work per thre...*Created by: aprokop*
Right now, strong scaling of OpenMP run will start increasing the OpenMP time for smaller problems, once the ratio of objects/thread hits certain threshold. We need to figure out the minimal amount of work per thread so that they won't be penalized.
**Summit 21 threads/smt1 construction filled box**
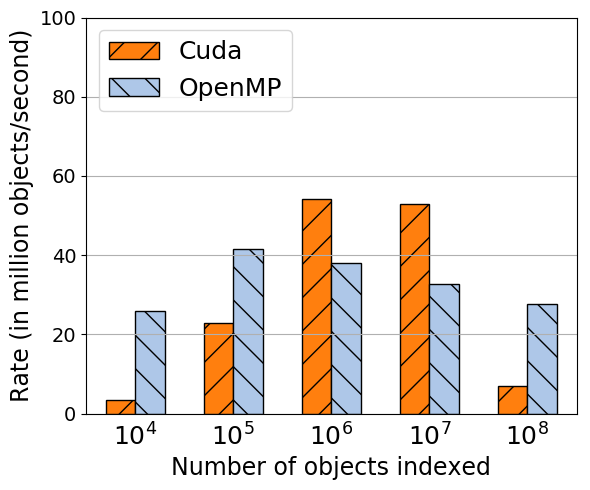
**Summit 168 threads/smt4 construction filled box**